

What led you to start working in the news content recommendation space?
I started my career in the energy industry in the US back in 2005. I worked 12 years in the Energy Industry. The energy industry is very data intensive and very early in my career I got exposed to big data projects. I definitely enjoyed it and, in hindsight, it was a blessing as well because Big Data Analytics has really taken off in the last 5 years. There is so much cloud computing power also readily available that the Big Data Analytics space is becoming very interesting.
That was my professional career. On the personal side I like to stay updated and keep myself abreast with developments. I get my news from various sources including news websites, social media, and of course specialist blogs. Around 2017 I felt it would be nice to marry my interest on Big Data Analytics and News and I transitioned from the energy industry’s Big Data Analytics to the Big Data Analytics of news content recommendation.
How this lead you to found Newsology?
As I mentioned above, I am an avid news consumer. However, I felt I was getting news recommendations from the general public – rather than experts and professionals in a certain domain. So, for example, I was getting articles about Nutrition from the general public, maybe my friends – and I felt I would rather read what Nutritionists are recommending. The hypothesis is that a professional in their domain is better informed about the quality of a news article.
We conducted multiple feedback sessions to test our hypothesis and we felt that there was a need to address this problem. So we started Newsology back in 2017. We got feedback from our user community and journalists along the way to ensure we are recommending good content to our users. We continue to get feedback on the recommendation of the articles our app suggests and we tweak our product accordingly.
What does a typical day look like?
I am definitely a night owl, so my typical ‘night’ begins with me analyzing our key KPI’s with the existing system, and then the completion status of the next improvements we are building – this could be tweaks to our AI engine, or modifications on our App. We work with a distributed team. We don’t have fixed schedules for meetings. Everyone is on Skype so we just message each other and, if necessary, set up conference calls.
So my night is used up for more of the technical work. Throughout the day I tend to do other tasks like Marketing, PR, and customer feedback related efforts.
What does your work setup look like? (your apps, productivity tools, etc.)
I have laptop connected with a dual-screen set up. I try to avoid writing long emails on my phone and keep that for my computer so I can give clear directions and answers. Our tasks are logged on Trello. We have very clear guidelines on how problems are logged on Trello, when is a task marked as complete, etc. We try to keep a culture of providing plenty of information to the next user so the task moves forward efficiently with minimal meetings. We are definitely an O365 shop. Our documents, KPI’s, workflows, presentations, etc are all stored on the O365 cloud. Apart from that, we use GitHub, and AWS.
How is AI surfacing original content?
There are a handful of news aggregation apps that use AI to surface original content. There are multiple ways those apps use AI to surface original content. I’ll explain two of the more common methods used, and then a twist that Newsology uses.
The first technology that can be used is Collaborative Filtering. We can explain Collaborative Filtering with a simple example. Let’s say Stephan is interested in Nutrition and Weight Loss. And Sarah is also interested in Nutrition, and Weight Loss. But Sarah is also interested in Seafood. Maybe we should recommend Seafood articles to Stephan? If Stephan exhibits a lack of interest towards Seafood articles, the model will recognize that and test another topic. You can see here that the AI engine is independently finding new topics that a reader might be interested in.
Let’s talk about a second technology: Doc2Vec. Sometimes there is an interesting perspective that a journalist or a blogger offers. And this gets drowned by a large volume of articles that are, essentially, talking about the same thing. We can use algorithms like Doc2Vec to see if journalists are talking about the same event. So, for example, let’s assume astrologist discover two interesting things about our galaxy on the same day. We might have 10 journalists cover the first event but only 1 journalist cover the 2nd event. Doc2Vec can identify that in reality the 10 journalists are discussing the same event, and their articles will be grouped into only one ‘display’. This gives a chance for the 2nd article to be shown to the users who are interested in Astrology. In this case, AI helped a user see developments that may otherwise be hidden away.
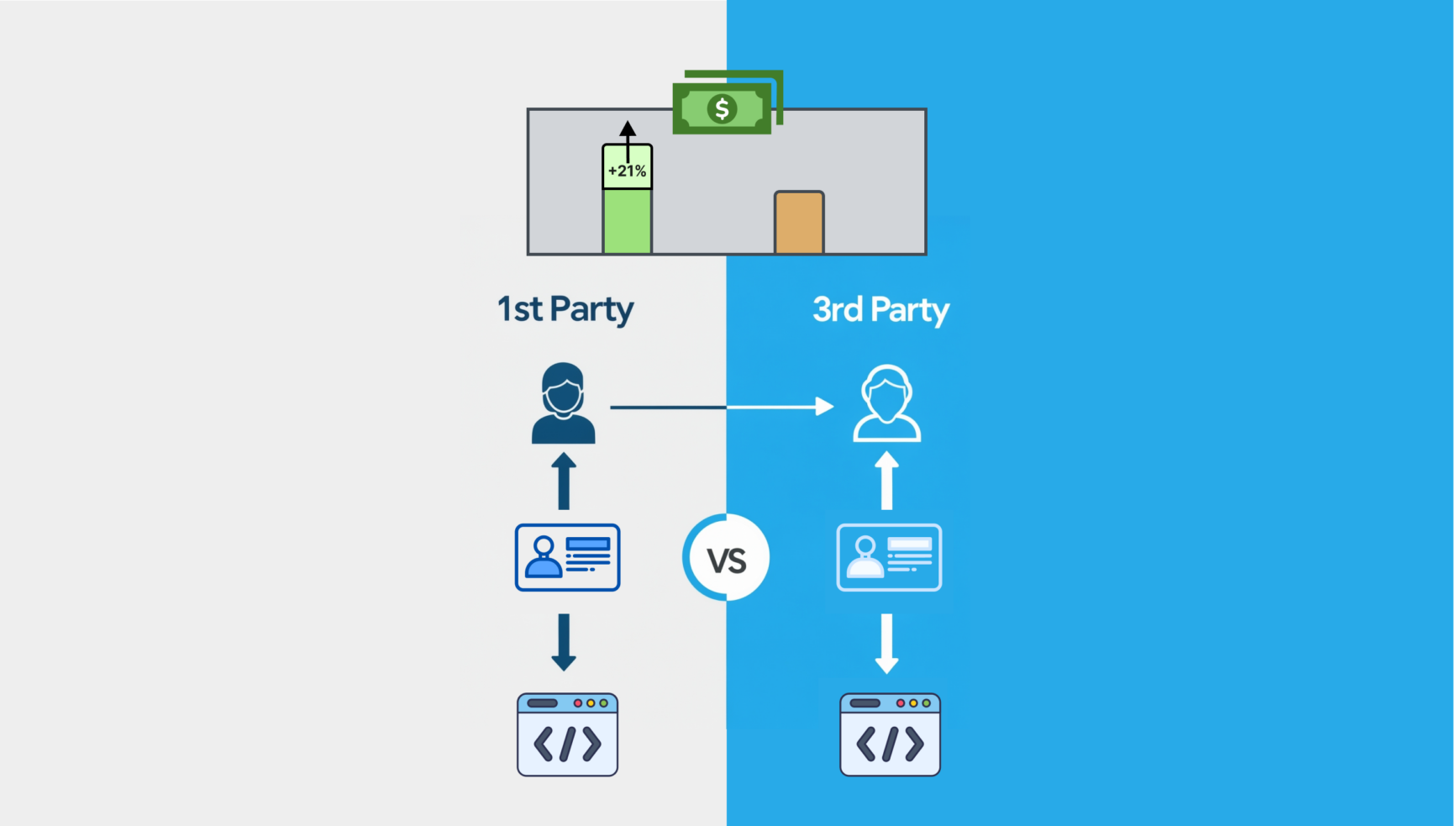
The twist that Newsology adds is that it also takes in what a user’s professional background is. Let’s use our first example with Sarah and Stephan. If a Newsology user states they are a nutritionist, we now add this third dimension in recommending articles to Sarah and Stephan about Nutrition articles. That is: what articles are nutritionist reading? Given this information, what can we now recommend to Sarah and Stephan?
Of course, there aren’t just two or three AI models used by news aggregation apps. There are many more models that work together, test together, and recommend together. They are also learning themselves if their recommendation is working. For example, is the user responding to the recommendation. This is known as A/B testing. And if the user is not responding, what do we do?
What is the benefit to bloggers and writers?
User want to consume original, well-articulated content. There are 1000’s of bloggers and writers who are writing original content that is not getting enough exposure. Newsology is helping surface the content of the independent bloggers and writers.
What are some delegation tips you stick to?
Delegation is a process. The first step is to use the Delegation Quadrant (important/not important vs Urgent/Not Urgent). You’d be surprised how many tasks fall out in that stage. If delegating, I find it is better to take the time to first write the vision/need/problem myself to make sure I have fully understood the problem and the desired end result. After thoroughly thinking through the task, I then ask myself who is the best person to assign the task to. It is important to lay out what a success looks like and encourage the delegate to ask themselves if they think a task is successfully completed. This ensures the individual completing the task is doing their own QC.
Content from our partners

What advice do you have for ambitious digital publishing and media professionals coming into the AI and ML space?
I’ll offer two advice. One soft skill, and one hard skill.
On the soft-skill side, spend a lot of time hiring the right person for the task. But once you have hired the person, don’t be afraid to hold your team to high standards. You’d be surprised how many people operate with the ‘good enough’ mentality. It’s not their fault. They are looking for guidance from you on what your expectations are.
On the hard skill side: AI and ML technologies can help you expose your content. Try to use tagging and keywords in your articles. The crawling engines are looking for these keywords. Also, don’t dilute your article. There are some publishers that add all kinds of keywords to their article. So, their article might be about hiking, but they add in the background keywords like “International Politics, time travel, etc”. AI engines can pick this up, and, if anything, it hurts showing your articles.






