

Chinas neues Deek Language Language Model (LLM) hat den von den USA dominierten Markt gestört und bietet ein relativ leistungsstarkes Chatbot-Modell zu erheblich geringeren Kosten.
Die reduzierten Entwicklungskosten und niedrigere Abonnementpreise im Vergleich zu US -KI -Tools trugen dazu bei, dass der amerikanische Chiphersteller über einen Tag 600 Milliarden US -Dollar (480 Milliarden Pfund) verlor Nvidia macht die Computer -Chips, die zur Ausbildung der Mehrheit der LLMs, der zugrunde liegenden Technologie in Chatgpt und anderen KI -Chatbots verwendet werden. Deepseek verwendet billigere Nvidia H800-Chips über die teureren hochmodernen Versionen.
Der Chatgpt Developer Openai hat Berichten zufolge zwischen 100 Mio. USD und 1 Milliarde US -Dollar für die Entwicklung einer aktuellen Version seines Produkts mit dem Namen O1 ausgegeben. Im Gegensatz dazu absolvierte Deepseek seine Ausbildung in nur zwei Monaten zu einem Preis von 5,6 Millionen US -Dollar mit einer Reihe von cleveren Innovationen.
Aber wie gut ist Deepseeks KI -Chatbot R1 mit anderen, ähnlichen KI -Tools zur Leistung verglichen?
Deepseek behauptet, dass seine Modelle vergleichsweise mit den OpenAI -Angeboten abschneiden und das O1 -Modell in bestimmten Benchmark -Tests übertreffen Benchmarks, die ein massives Multitasking -Sprachverständnis (MMLU) verwenden, bewerten jedoch das Wissen über mehrere Probanden hinweg unter Verwendung von Multithip -Fragen. Viele LLMs sind für solche Tests ausgebildet und optimiert, was sie als echte Indikatoren für die reale Leistung unzuverlässig macht.
Eine alternative Methodik zur objektiven Bewertung von LLMs verwendet eine Reihe von Tests, die von Forschern der Universitäten von Cardiff Metropolitan, Bristol und Cardiff entwickelt wurden - kollektiv als Wissensbeobachtungsgruppe (KOG) bekannt. Diese Tests untersuchen die Fähigkeit der LLMs, menschliche Sprache und Wissen durch Fragen nachzuahmen, die implizite menschliches Verständnis erfordern, um zu beantworten. Die Kerntests werden geheim gehalten, um zu vermeiden, dass LLM -Unternehmen ihre Modelle für diese Tests ausbilden.
Kog hat öffentliche Tests eingesetzt, die von der Arbeit von Colin Fraser, einem Datenwissenschaftler bei Meta , um Deepseek gegen andere LLMs zu bewerten. Die folgenden Ergebnisse wurden beobachtet:
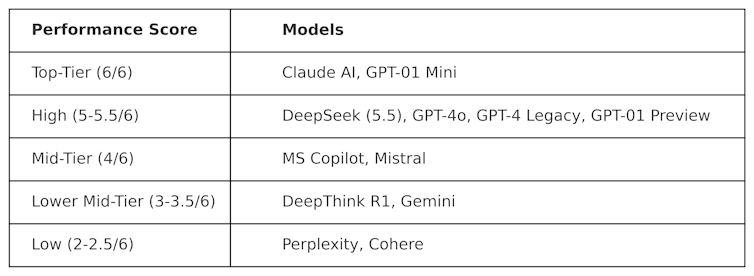
Die Tests zur Erzeugung dieser Tabelle sind in der Natur „kontrovers“. Mit anderen Worten, sie sind so konzipiert, dass sie „hart“ sind und LLMs auf eine Weise testen können, die nicht mit der Art und Weise sympathisch ist. Dies bedeutet, dass die Leistung dieser Modelle in diesem Test wahrscheinlich von ihrer Leistung bei Mainstream -Benchmarking -Tests unterscheidet.
Deepseek erzielte 5,5 von 6 und übertraf OpenAs O1-sein fortgeschrittenes Argument (bekannt als „Kette des Gedankens“) sowie Chatgpt-4o, die kostenlose Version von Chatgpt. Aber Deepseek wurde von Anthropics Claudeai und Openais O1 Mini, beide einen perfekten 6/6, übertroffen. Es ist interessant, dass O1 gegen sein „kleineres“ Gegenstück O1 Mini unterdurchschnittlich war.
DeeptHink R1-ein KI-Werkzeug, das von Deepseek hergestellt wurde, wurde im Vergleich zu Deepseek mit einer Punktzahl von 3,5 unterdurchschnittlich.
Dieses Ergebnis zeigt, wie wettbewerbsfähiger Deepseeks Chatbot bereits ist und OpenAs Flaggschiff -Modelle besiegt. Es wird wahrscheinlich die weitere Entwicklung für Deepseek ankurbeln, die nun eine starke Grundlage hat, auf der man aufbauen kann. Das chinesische Technologieunternehmen hat jedoch ein ernstes Problem, das die anderen LLMs nicht haben: Zensur.
Zensurherausforderungen
Trotz seiner starken Leistung und Popularität hat Deepseek kritisiert, dass seine Reaktionen auf politisch sensible Themen in China reagieren. Zum Beispiel werden Eingabeaufforderungen im Zusammenhang mit dem Square auf dem Tiananmen, Taiwan, Uyghur -Muslimen und demokratischen Bewegungen mit der Antwort begegnet: „Entschuldigung, das liegt außerhalb meines aktuellen Geltungsbereichs.“
Dieses Problem ist jedoch nicht unbedingt nur für Deepseek und das Potenzial für politische Einfluss und Zensur in LLMs allgemeiner ist ein wachsendes Problem. Die Ankündigung von Donald Trumps 500 -Milliarden -Dollar -Stargate LLM -Projekt in Höhe von Openai, Nvidia, Oracle, Microsoft und Arm wirft ebenfalls die Ängste vor politischem Einfluss auf.
Darüber hinaus deutet die jüngste Entscheidung von Meta, die Überprüfung von Fakten auf Facebook und Instagram aufzugeben, auf einen zunehmenden Trend zum Populismus über die Wahrhaftigkeit hin.
Inhalte unserer Partner



Die Ankunft von Deepseek hat den LLM -Markt schwerwiegende Störungen verursacht. US -Unternehmen wie OpenAI und Anthropic werden gezwungen sein, ihre Produkte zu innovieren, um die Relevanz aufrechtzuerhalten und deren Leistung und Kosten entsprechen.
Der Erfolg von Deepseek stellt bereits den Status Quo in Frage und zeigt, dass LLM-Modelle mit leistungsstarken LLM ohne Milliarden-Dollar-Budget entwickelt werden können. Es unterstreicht auch die Risiken der LLM -Zensur, die Ausbreitung von Fehlinformationen und warum unabhängige Bewertungen wichtig sind.
Da LLMs in globaler Politik und Wirtschaft tiefer eingebettet werden, werden Transparenz und Rechenschaftspflicht von wesentlicher Bedeutung sein, um sicherzustellen, dass die Zukunft von LLMs sicher, nützlich und vertrauenswürdig ist.
Simon Thorne, Senior Dozent für Computer- und Informationssysteme, Cardiff Metropolitan University
Dieser Artikel wird aus dem Gespräch unter einer Creative Commons -Lizenz neu veröffentlicht. Lesen Sie den Originalartikel .






