

El nuevo Modelo de Lenguaje de Lenguas de Deepseek (LLM) de China ha interrumpido el mercado dominado por los Estados Unidos , ofreciendo un modelo de chatbot de rendimiento relativamente alto a un costo significativamente más bajo.
El costo reducido de desarrollo y los precios de suscripción más bajos en comparación con las herramientas de IA de EE. UU. Contribuyeron al fabricante de chips estadounidense Nvidia que perdió US $ 600 mil millones (£ 480 mil millones) en valor de mercado durante un día. Nvidia hace que los chips de la computadora se utilicen para entrenar a la mayoría de los LLM, la tecnología subyacente utilizada en ChatGPT y otros chatbots de IA. Deepseek utiliza chips Nvidia H800 más baratos sobre las versiones de última generación.
Según los informes, el desarrollador de ChatGPT Openai gastó entre US $ 100 millones y US $ 1 mil millones en el desarrollo de una versión muy reciente de su producto llamado O1. En contraste, Deepseek realizó su capacitación en solo dos meses a un costo de US $ 5.6 millones utilizando una serie de innovaciones inteligentes.
Pero, ¿qué tan bien se compara con otras herramientas de IA similares en el rendimiento de Deepseek's AI, R1, se compara con otras herramientas de IA similares en el rendimiento?
Deepseek afirma que sus modelos funcionan de manera comparable a las ofertas de OpenAI, incluso excediendo el modelo O1 en ciertas pruebas de referencia. Sin embargo, los puntos de referencia que utilizan pruebas de comprensión de lenguaje multitarea masiva (MMLU) evalúan el conocimiento en múltiples materias utilizando preguntas de opción múltiple. Muchos LLM están capacitados y optimizados para tales pruebas, lo que las hace poco confiables como verdaderos indicadores de rendimiento del mundo real.
Una metodología alternativa para la evaluación objetiva de LLMS utiliza un conjunto de pruebas desarrolladas por investigadores de las universidades Metropolitan, Bristol y Cardiff de Cardiff, conocidas colectivamente como el Grupo de Observación del Conocimiento (KOG). Estas pruebas sondean la capacidad de LLM para imitar el lenguaje y el conocimiento humano a través de preguntas que requieren una comprensión humana implícita para responder. Las pruebas centrales se mantienen en secreto, para evitar que las compañías de LLM entrenen sus modelos para estas pruebas.
KOG desplegó pruebas públicas inspiradas en el trabajo de Colin Fraser, científico de datos de Meta , para evaluar a Deepseek contra otros LLM. Se observaron los siguientes resultados:
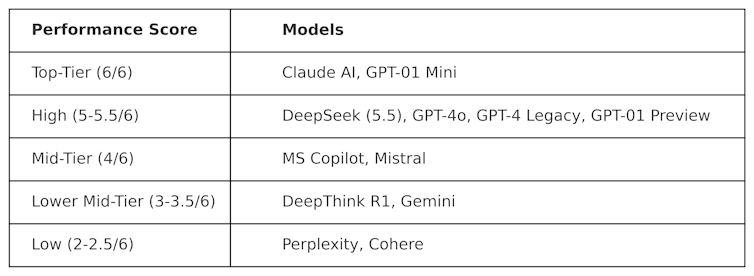
Las pruebas utilizadas para producir esta tabla son de naturaleza "adversaria". En otras palabras, están diseñados para ser "duros" y para probar LLM de una manera que no simpatizan con la forma en que están diseñados. Esto significa que es probable que el rendimiento de estos modelos en esta prueba sea diferente a su rendimiento en las pruebas de evaluación comparativa convencional.
Deepseek obtuvo 5.5 de 6, superando el O1 de Openai, su razonamiento avanzado (conocido como modelo de "cadena de pensamiento"), así como ChatGPT-4O, la versión gratuita de ChatGPT. Pero Deepseek fue superado marginalmente por Claudeai de Anthrope y Openi's O1 Mini, los cuales obtuvieron un 6/6 perfecto. Es interesante que O1 haya tenido un rendimiento inferior contra su contraparte "más pequeña", O1 Mini.
DeepThink R1, una herramienta de IA de cadena de pensamiento hecha por Deepseek, tuvo un rendimiento inferior en comparación con Deepseek con una puntuación de 3.5.
Este resultado muestra cuán competitivo ya es el chatbot de Deepseek, superando a los modelos insignia de OpenAI. Es probable que estimule un mayor desarrollo para Deepseek, que ahora tiene una base sólida para construir. Sin embargo, la compañía tecnológica china tiene un problema grave que los otros LLM no: la censura.
Desafíos de censura
A pesar de su fuerte desempeño y popularidad, Deepseek ha enfrentado críticas por sus respuestas a temas políticamente sensibles en China. Por ejemplo, las indicaciones relacionadas con la Plaza Tiananmen, Taiwán, los musulmanes uigures y los movimientos democráticos se encuentran con la respuesta: "Lo siento, eso está más allá de mi alcance actual".
Pero este problema no es necesariamente exclusivo de Deepseek, y el potencial de influencia política y censura en LLMS en general es una preocupación creciente. proyecto Stargate LLM de US $ 500 mil millones de Donald Trump , que involucra OpenAi, Nvidia, Oracle, Microsoft y ARM, también plantea temores de influencia política.
Además, la reciente decisión de Meta de abandonar la verificación de hechos en Facebook e Instagram sugiere una tendencia creciente hacia el populismo sobre la verdad.
Contenido de nuestros socios



La llegada de Deepseek ha causado graves interrupciones en el mercado de LLM. Las compañías estadounidenses como OpenAI y Anthrope se verán obligadas a innovar sus productos para mantener relevancia y igualar su rendimiento y costo.
El éxito de Deepseek ya está desafiando el status quo, lo que demuestra que los modelos LLM de alto rendimiento pueden desarrollarse sin presupuestos de mil millones de dólares. También destaca los riesgos de la censura de LLM, la propagación de la información errónea y por qué las evaluaciones independientes son importantes.
A medida que los LLM se integran más profundamente en la política y los negocios globales, la transparencia y la responsabilidad serán esenciales para garantizar que el futuro de los LLM sea seguro, útil y confiable.
Simon Thorne, profesor titular de sistemas de informática e información, Universidad Metropolitana de Cardiff
Este artículo se vuelve a publicar a partir de la conversación bajo una licencia Creative Commons. Lea el artículo original .






