

La semana pasada, el multimillonario y propietario de X, Elon Musk, afirmó que el conjunto de datos generados por humanos que se utiliza para entrenar modelos de inteligencia artificial (IA) como ChatGPT se ha agotado.
Musk no citó evidencia que respalde esto. Pero otras figuras destacadas de la industria tecnológica han hecho afirmaciones similares en los últimos meses. Y investigaciones anteriores indicaron que los datos generados por humanos se agotarían en un plazo de dos a ocho años.
Esto se debe en gran medida a que los humanos no pueden crear nuevos datos, como texto, vídeo e imágenes, con la suficiente rapidez para satisfacer las rápidas y enormes demandas de los modelos de IA. Cuando se agoten los datos genuinos, se presentará un problema importante tanto para los desarrolladores como para los usuarios de la IA.
Obligará a las empresas de tecnología a depender más de los datos generados por la IA, conocidos como “datos sintéticos”. Y esto, a su vez, podría llevar a que los sistemas de inteligencia artificial que actualmente utilizan cientos de millones de personas sean menos precisos y confiables y, por lo tanto, menos útiles.
Pero este no es un resultado inevitable. De hecho, si se utilizan y gestionan con cuidado, los datos sintéticos podrían mejorar los modelos de IA.

Los problemas con los datos reales
Las empresas de tecnología dependen de datos (reales o sintéticos) para construir, entrenar y perfeccionar modelos de IA generativa como ChatGPT. La calidad de estos datos es crucial. Los datos deficientes conducen a resultados deficientes, de la misma manera que el uso de ingredientes de baja calidad en la cocina puede producir comidas de baja calidad.
Los datos reales se refieren a textos, vídeos e imágenes creados por humanos. Las empresas lo recopilan a través de métodos como encuestas, experimentos, observaciones o minería de sitios web y redes sociales.
Los datos reales generalmente se consideran valiosos porque incluyen eventos reales y capturan una amplia gama de escenarios y contextos. Sin embargo, no es perfecto.
Por ejemplo, puede contener errores ortográficos y contenido inconsistente o irrelevante . También puede estar muy sesgado , lo que puede, por ejemplo, llevar a que modelos generativos de IA creen imágenes que muestren solo a hombres o personas blancas en ciertos trabajos.
Este tipo de datos también requiere mucho tiempo y esfuerzo para prepararse. Primero, las personas recopilan conjuntos de datos antes de etiquetarlos para que sean significativos para un modelo de IA. Luego revisarán y limpiarán estos datos para resolver cualquier inconsistencia, antes de que las computadoras los filtren, organicen y validen.
Este proceso puede llevar hasta el 80% del tiempo total invertido en el desarrollo de un sistema de IA.
Pero como se indicó anteriormente, los datos reales también escasean cada vez más porque los humanos no pueden producirlos lo suficientemente rápido para satisfacer la creciente demanda de IA.
El auge de los datos sintéticos
Los datos sintéticos se crean o generan artificialmente mediante algoritmos , como el texto generado por ChatGPT o una imagen generada por DALL-E .
En teoría, los datos sintéticos ofrecen una solución rentable y más rápida para entrenar modelos de IA.
También aborda preocupaciones de privacidad y cuestiones éticas , particularmente con información personal sensible como datos de salud.
Es importante destacar que, a diferencia de los datos reales, no escasean. De hecho, es ilimitado.
De aquí en adelante sus únicos datos sintéticos.
-Rohan Paul (@rohanpaul_ai) 9 de enero de 2025
"La suma acumulada de conocimientos humanos se ha agotado en el entrenamiento de la IA. Eso ocurrió, básicamente, el año pasado".
– Elon pic.twitter.com/rdPzCbvdLv
Los desafíos de los datos sintéticos
Por estas razones, las empresas de tecnología recurren cada vez más a datos sintéticos para entrenar sus sistemas de inteligencia artificial. La firma de investigación Gartner estima que para 2030, los datos sintéticos se convertirán en la principal forma de datos utilizados en la IA.
Pero aunque los datos sintéticos ofrecen soluciones prometedoras, no están exentos de desafíos.
Una de las principales preocupaciones es que los modelos de IA puedan "colapsar" cuando dependen demasiado de datos sintéticos. Esto significa que comienzan a generar tantas “alucinaciones” (una respuesta que contiene información falsa) y su calidad y rendimiento disminuyen tanto que ya no se pueden utilizar.
Por ejemplo, los modelos de IA ya tienen dificultades para escribir correctamente algunas palabras. Si estos datos plagados de errores se utilizan para entrenar otros modelos, es probable que ellos también repliquen los errores.
Contenido de nuestros socios

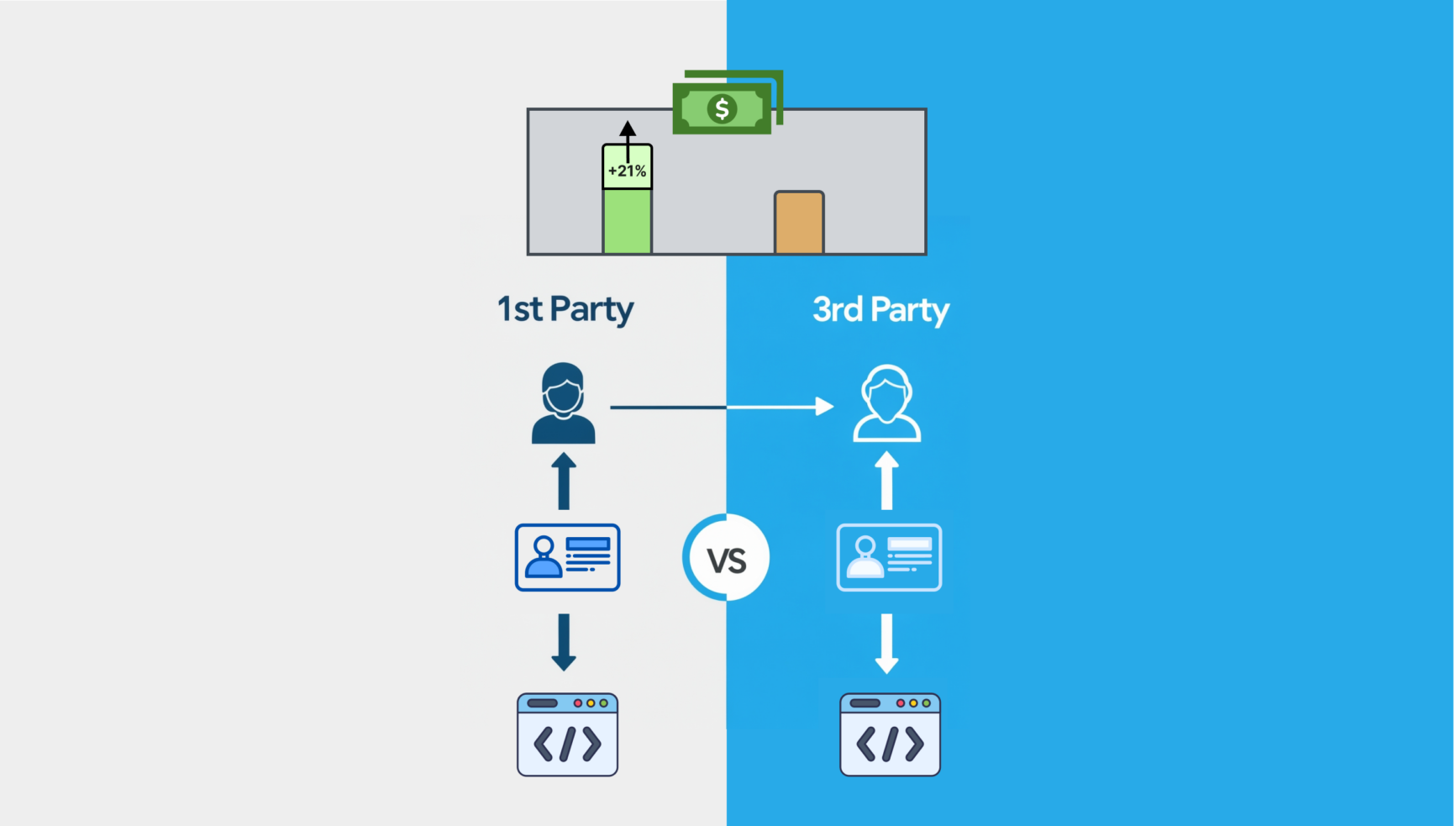
Los datos sintéticos también conllevan el riesgo de ser demasiado simplistas . Puede carecer de los detalles matizados y la diversidad que se encuentran en los conjuntos de datos reales, lo que podría dar como resultado que la producción de modelos de IA entrenados en ellos también sea demasiado simplista y menos útil.
Crear sistemas sólidos para mantener la IA precisa y confiable
Para abordar estos problemas, es esencial que los organismos y organizaciones internacionales como la Organización Internacional de Normalización o la Unión Internacional de Telecomunicaciones introduzcan sistemas sólidos para rastrear y validar los datos de entrenamiento de IA, y garantizar que los sistemas puedan implementarse globalmente.
Los sistemas de inteligencia artificial pueden equiparse para rastrear metadatos, lo que permite a los usuarios o sistemas rastrear los orígenes y la calidad de cualquier dato sintético con el que hayan sido entrenados. Esto complementaría un sistema de seguimiento y validación estándar a nivel mundial.
Los humanos también deben supervisar los datos sintéticos durante todo el proceso de entrenamiento de un modelo de IA para garantizar que sean de alta calidad. Esta supervisión debe incluir la definición de objetivos, la validación de la calidad de los datos, la garantía del cumplimiento de estándares éticos y el seguimiento del rendimiento del modelo de IA.
Irónicamente, los algoritmos de IA también pueden desempeñar un papel en la auditoría y verificación de datos, garantizando la precisión de los resultados generados por IA a partir de otros modelos. Por ejemplo, estos algoritmos pueden comparar datos sintéticos con datos reales para identificar cualquier error o discrepancia y garantizar que los datos sean consistentes y precisos. De esta manera, los datos sintéticos podrían conducir a mejores modelos de IA.
El futuro de la IA depende de datos de alta calidad . Los datos sintéticos desempeñarán un papel cada vez más importante para superar la escasez de datos.
Sin embargo, su uso debe gestionarse cuidadosamente para mantener la transparencia, reducir los errores y preservar la privacidad, garantizando que los datos sintéticos sirvan como un complemento confiable de los datos reales, manteniendo los sistemas de IA precisos y confiables.
James Jin Kang, profesor titular de informática, Universidad RMIT de Vietnam .
Este artículo se vuelve a publicar desde The Conversation bajo una licencia Creative Commons. Lea el artículo original .






