

Le nouveau modèle de grande langue (LLM) en Chine a perturbé le marché dominé par les États-Unis , offrant un modèle de chatbot relativement performant à un coût nettement inférieur.
Le coût de développement réduit et la baisse des prix d'abonnement par rapport aux outils d'IA américains ont contribué au fabricant de puces américain Nvidia perdant 600 milliards de dollars US (480 milliards de livres sterling) en valeur marchande sur une journée. NVIDIA fait que les puces informatiques forment la majorité des LLM, la technologie sous-jacente utilisée dans Chatgpt et d'autres chatbots d'IA. Deepseek utilise des puces Nvidia H800 moins chères sur les versions plus chères de pointe.
Le développeur de Chatgpt Openai aurait dépensé entre 100 millions de dollars et 1 milliard de dollars américains pour le développement d'une version très récente de son produit appelé O1. En revanche, Deepseek a réalisé sa formation en seulement deux mois au coût de 5,6 millions de dollars américains en utilisant une série d'innovations intelligentes.
Mais à quel point le chatbot AI de Deepseek, R1, se compare-t-il avec d'autres outils d'IA similaires sur les performances?
Deepseek affirme que ses modèles fonctionnent de manière comparable aux offres d'Openai, dépassant même le modèle O1 dans certains tests de référence. Cependant, les repères qui utilisent des tests massifs de compréhension du langage multitâche (MMLU) évaluent les connaissances sur plusieurs sujets en utilisant des questions à choix multiples. De nombreux LLM sont formés et optimisés pour de tels tests, ce qui les rend peu fiables comme de véritables indicateurs de performances réelles.
Une méthodologie alternative pour l'évaluation objective des LLM utilise un ensemble de tests développés par des chercheurs de Cardiff Metropolitan, Bristol et Cardiff Universities - connue collectivement sous le nom de Group d'observation des connaissances (KOG). Ces tests sondent la capacité des LLMS à imiter le langage humain et les connaissances à travers des questions qui nécessitent une compréhension humaine implicite pour répondre. Les tests de base sont gardés secrètes, pour éviter que les entreprises LLM forment leurs modèles pour ces tests.
KOG a déployé des tests publics inspirés par les travaux de Colin Fraser, un scientifique des données chez Meta , pour évaluer Deepseek contre d'autres LLM. Les résultats suivants ont été observés:
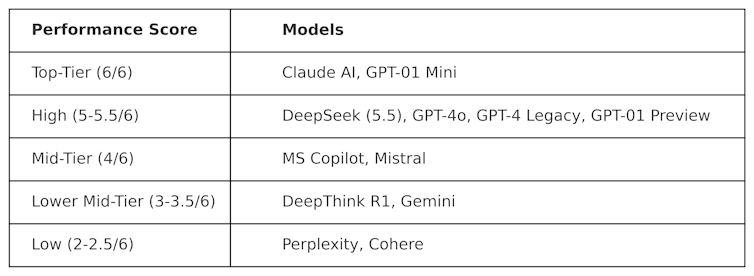
Les tests utilisés pour produire ce tableau sont de nature «contradictoire». En d'autres termes, ils sont conçus pour être «durs» et pour tester les LLM de manière qui ne sympathisait pas à la façon dont ils sont conçus. Cela signifie que les performances de ces modèles dans ce test sont probablement différentes de leurs performances dans les tests d'analyse comparative traditionnels.
Deepseek a marqué 5,5 sur 6, surperformant le modèle O1 - son raisonnement avancé (connu sous le nom de «chaîne de réflexion») - ainsi que ChatGPT-4O, la version gratuite de Chatgpt. Mais Deepseek a été marginalement surperformé par Claudeai d'Anthropic et O1 Mini d'Openai, qui a tous deux marqué un 6/6 parfait. Il est intéressant que O1 ait sous-performé contre son homologue «plus petit», O1 Mini.
Deepthink R1 - un outil d'IA en chaîne de pensées fabriqué par Deepseek - sous-performé par rapport à Deepseek avec un score de 3,5.
Ce résultat montre à quel point le chatbot de Deepseek compétitif est déjà, battant les modèles phares d'Openai. Il est susceptible de stimuler le développement de Deepseek, qui a désormais une base solide sur laquelle s'appuyer. Cependant, la société de technologie chinoise a un problème grave que les autres LLM ne le font pas: la censure.
Défis de censure
Malgré sa forte performance et sa popularité, Deepseek a fait face à des critiques sur ses réponses à des sujets politiquement sensibles en Chine. Par exemple, les invites liées à Tiananmen Square, Taiwan, les musulmans ouïghour et les mouvements démocratiques sont rencontrés par la réponse: «Désolé, cela dépasse ma portée actuelle.»
Mais cette question n'est pas nécessairement unique à Deepseek, et le potentiel d'influence politique et de censure dans les LLM est généralement une préoccupation croissante. projet de Stargate LLM de Donald Trump , impliquant Openai, Nvidia, Oracle, Microsoft et ARM, suscite également des craintes d'influence politique.
De plus, la récente décision de Meta d' abandonner la vérification des faits sur Facebook et Instagram suggère une tendance croissante vers le populisme sur la véracité.
Contenu de nos partenaires



L'arrivée de Deepseek a provoqué de graves perturbations sur le marché LLM. Les entreprises américaines telles que OpenAI et anthropic seront obligées d'innover leurs produits pour maintenir la pertinence et égaler ses performances et ses coûts.
Le succès de Deepseek conteste déjà le statu quo, démontrant que les modèles LLM haute performance peuvent être développés sans budgets d'un milliard de dollars. Il met également en évidence les risques de censure LLM, la propagation de la désinformation et pourquoi les évaluations indépendantes sont importantes.
À mesure que les LLM sont plus profondément ancrées dans la politique et les entreprises mondiales, la transparence et la responsabilité seront essentielles pour garantir que l'avenir des LLM est sûr, utile et digne de confiance.
Simon Thorne, maître de conférences en informatique et systèmes d'information, Cardiff Metropolitan University
Cet article est republié à partir de la conversation sous une licence Creative Commons. Lisez l' article original .






