


Forrige ukes hovedtale for Google I/O 2023 klarte å sette i gang nye AI-alarmklokker i publiseringsfellesskapet som jeg ikke er overbevist om var berettiget.
Vi har sett forskjellige advarsler om farene og mulighetene ved AI i månedene siden ChatGPT ble lansert. Noen utgivere investerer i dedikerte AI-team, mens andre mumler mørkt om å ta rettslige skritt mot AI-utviklere på grunn av plagiering.
Imidlertid traff VP Engineering hos Google Cathy Edwards sin oppdatering om hvordan Bard ville forme søkeresultater i nær fremtid helt klart en frisk nerve, med en Forbes-bidragsyter som sammenlignet det med en atombombe som ble sluppet på digitale utgivere .
Jeg så selv på Edwards utstillingsvindu, og forhåpentligvis uten å høres blasert ut, er jeg mye mindre bekymret. Jeg vil anbefale å ta deg tid til å se segmentet selv før du fortsetter. Fortsett, det er ikke så lenge og jeg venter, jeg lover.
Bards evne til å svare på brede spørsmål ved å "lese" live-artikler har skapt frykt for at Googles brukere ikke lenger vil ha en grunn til å klikke seg videre til de originale artiklene. Sammenligningen som er gjort er Wikipedia og dens kilder - mange bruker Wikipedia, bare en brøkdel klikker på kildene.
Jeg kjøper ikke den sammenligningen av flere grunner. La meg bruke Edwards' presentasjon for å illustrere poenget mitt.
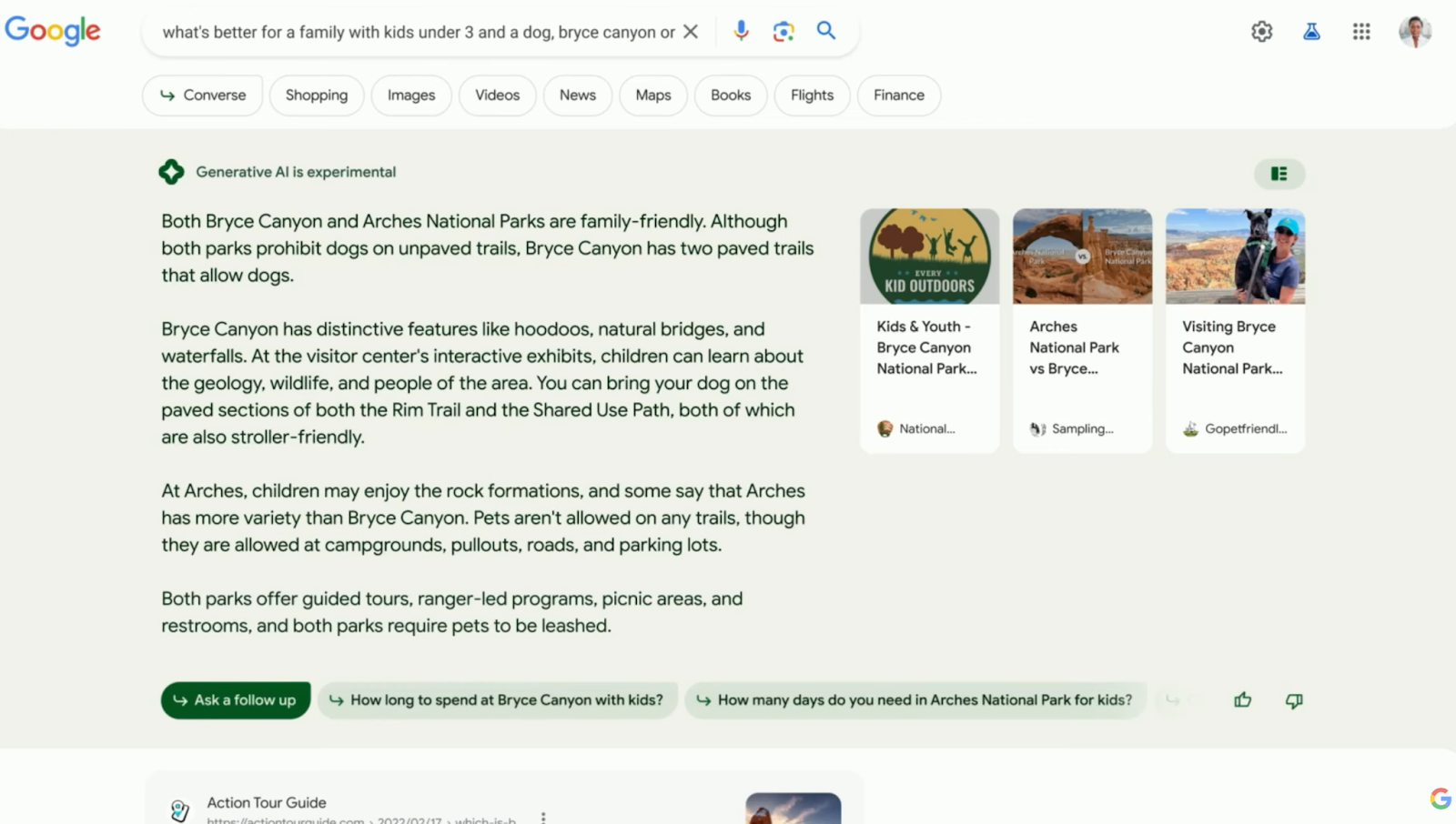
Spørsmål, men ingen svar?
Når jeg så på spørsmålet og det påfølgende svaret, dukket et par ting opp for meg fra starten.
Det er ett spørsmål med to påvirkningsfaktorer. Hvilken park er bedre for en familie med a) barn under tre og b) en hund. Bard unnlater ikke bare å svare på spørsmålet, men også en av faktorene som påvirker det.
Søket leter etter en anbefaling, men AI gir ingen. I stedet prøver den å adressere de påvirkningsfaktorene. Men uten informasjon tilgjengelig om aktiviteter for barn under tre år, avviser Bard svaret sitt ved å gjennomgå generiske barneaktiviteter. AI er i stand til å gi litt grunnleggende informasjon om hundetilgjengelighet.
Hvor mye svarte dette øyeblikksbildet på det opprinnelige søket? Veldig lite, vil jeg påstå. Det har startet prosessen med å etablere filtre. For eksempel, hvis familien absolutt elsker hunden sin og ser etter en tur, så er Bryce Canyon det. Men hvis de elsker hunden sin og vil campe, så går de for Arches.
Bard-øyeblikket er langt fra et definitivt svar og fungerer som et utgangspunkt for forskningsreisen. Dette betyr at når søkere bruker Bard, vil de raskere kunne komme inn på artiklene som faktisk har innholdet de ønsker å lese, i stedet for å skumme over.
Bard syntetiserer svarene sine basert på informasjonen i artiklene den leser, men den har ikke kapasitet til å ekstrapolere derfra. Og når AI har muligheten, hvor mange lesere vil iboende stole på en maskins anbefalinger om ferie- eller matdestinasjoner? Tross alt kreves det en kropp for å forstå verden .
Innhold fra våre partnere



Vi kan diskutere publikumsverdi og beregninger som rulledybde i lengden, men jeg er ikke sikker på at det er et behov. Disse AI-genererte øyeblikksbildene er ikke nok til å erstatte en personlig vurdering av høy kvalitet av naturparker, og dette strekker seg til andre aspekter av publiseringsverdenen. Personlige erfaringer vil trumfe faktamaskiner. Tross alt, hvor mange familier klemmer seg rundt Wikipedia på en kveld i stedet for den siste reality-TV-serien?
Så hva betyr alt dette for utgivere? Utvikle seg eller dø, vil jeg påstå. Møt publikumsbehov ved å lage innhold av høy kvalitet som AI rett og slett ikke har referanserammen til å produsere.



