


O discurso principal do Google I/O 2023 da semana passada conseguiu disparar novos alarmes de IA na comunidade editorial que não estou convencido de que fossem justificados.
Vimos vários avisos sobre os perigos e oportunidades da IA nos meses desde o lançamento do ChatGPT. Alguns editores estão investindo em equipes dedicadas de IA, enquanto outros murmuram sombriamente sobre tomar medidas legais contra desenvolvedores de IA por plágio.
No entanto, a atualização da vice-presidente de engenharia do Google Cathy Edwards sobre como Bard moldaria os resultados de pesquisa em um futuro próximo atingiu claramente um novo nervo, com um colaborador da Forbes comparando-o a uma bomba nuclear lançada sobre editores digitais .
Eu mesmo assisti o showcase de Edwards e, espero que sem parecer blasé, estou muito menos preocupado. Eu recomendo reservar um tempo para assistir ao segmento antes de continuar. Vá em frente, não demora tanto e vou esperar, prometo.
A capacidade de Bard de responder a perguntas amplas “lendo” artigos ao vivo alimentou temores de que os usuários do Google não terão mais motivos para clicar nos artigos originais. A comparação feita é a Wikipédia e suas fontes – muitas pessoas usam a Wikipédia, apenas uma fração de clique nas fontes.
Não acredito nessa comparação por alguns motivos. Deixe-me usar a apresentação de Edwards para ilustrar meu argumento.
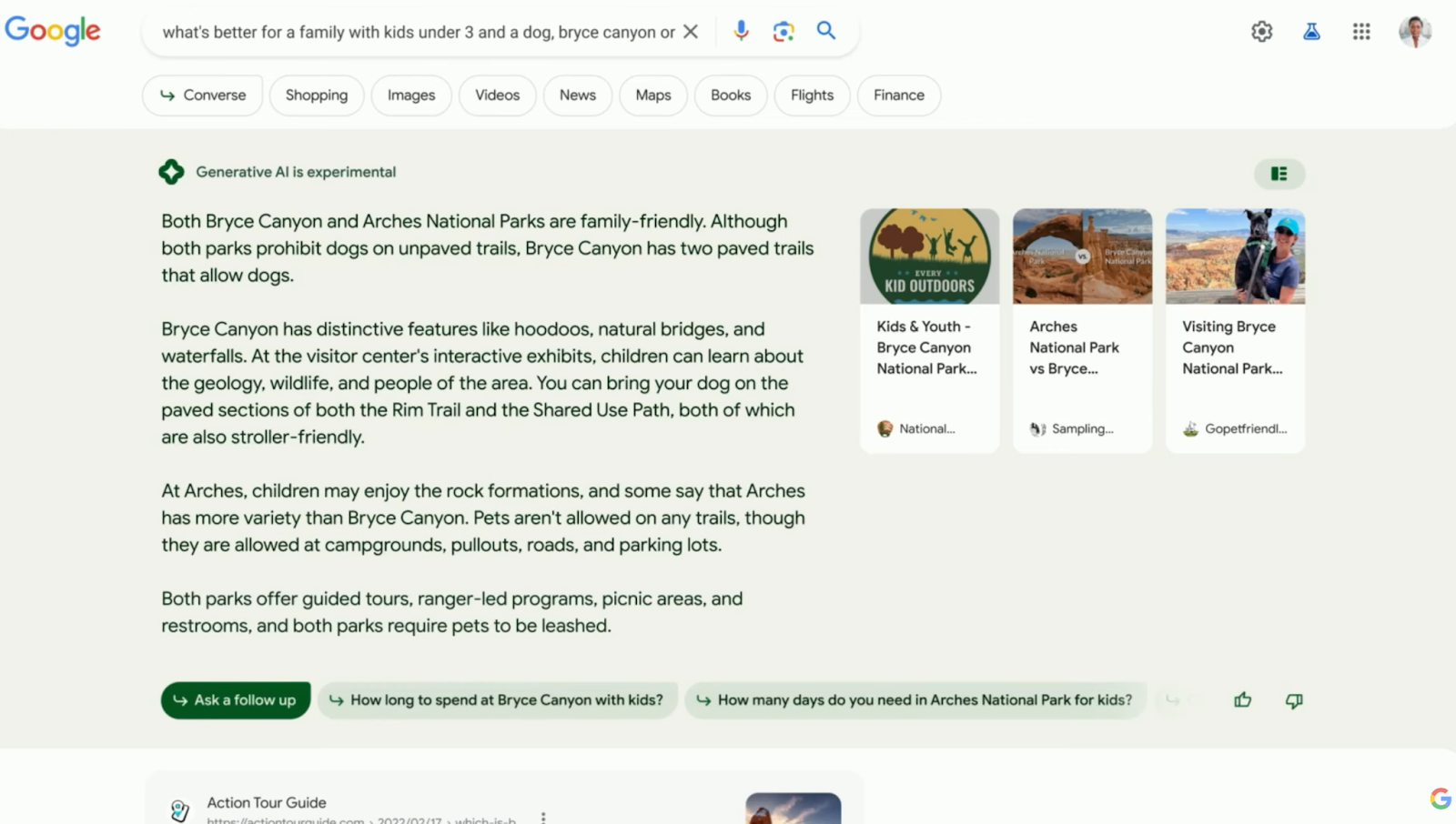
Perguntas, mas sem respostas?
Olhando para a pergunta e a resposta subsequente, algumas coisas me ocorreram desde o início.
Há uma pergunta com dois fatores de influência. Qual parque é melhor para uma família com a) crianças menores de três anos eb) um cachorro. Bard não apenas falha em responder à pergunta, mas também a um dos fatores que influenciam.
A consulta de pesquisa procura uma recomendação, mas a IA não fornece nenhuma. Em vez disso, tenta abordar os fatores que influenciam. No entanto, sem informação disponível sobre atividades para crianças menores de três anos, Bard falsifica a sua resposta ao rever atividades genéricas para crianças. A IA é capaz de fornecer algumas informações básicas sobre a acessibilidade dos cães.
Quanto esse instantâneo respondeu à consulta de pesquisa original? Muito pouco, eu diria. Iniciou o processo de estabelecimento de filtros. Por exemplo, se a família adora seu cachorro e está procurando passear, então é Bryce Canyon. Mas se eles amam seu cachorro e querem acampar, então irão para Arches.
O instantâneo de Bard está longe de ser uma resposta definitiva e serve como ponto de partida para a jornada de pesquisa. Isso significa que, à medida que os pesquisadores usam o Bard, eles serão capazes de localizar mais rapidamente os artigos que realmente têm o conteúdo que desejam ler, em vez de folheá-los.
Bard sintetiza suas respostas com base nas informações contidas nos artigos que lê, mas não tem capacidade de extrapolar a partir daí. E quando a IA tiver essa capacidade, quantos leitores confiarão inerentemente nas recomendações de uma máquina sobre destinos de férias ou alimentação? Afinal, é preciso um corpo para compreender o mundo .
Conteúdo de nossos parceiros



Poderíamos discutir detalhadamente o valor do público e métricas, como profundidade de rolagem, mas não tenho certeza se há necessidade. Esses instantâneos gerados por IA não são suficientes para substituir uma análise pessoal de alta qualidade dos parques naturais e isso se estende a outros aspectos do mundo editorial. As experiências pessoais superarão as máquinas de fatos. Afinal, quantas famílias se reúnem em torno da Wikipédia à noite, em vez de ver os últimos reality shows da TV?
Então, o que tudo isso significa para os editores? Evolua ou morra, eu diria. Atenda às necessidades do público criando conteúdo de alta qualidade que a IA simplesmente não tem referência para produzir.



