

Na semana passada, o bilionário e proprietário do X, Elon Musk, afirmou que o conjunto de dados gerados por humanos usados para treinar modelos de inteligência artificial (IA), como o ChatGPT, acabou.
Musk não citou evidências para apoiar isso. Mas outras figuras importantes da indústria tecnológica fizeram afirmações semelhantes nos últimos meses. E pesquisas anteriores indicavam que os dados gerados por humanos se esgotariam dentro de dois a oito anos.
Isto ocorre em grande parte porque os humanos não conseguem criar novos dados, como texto, vídeo e imagens, com rapidez suficiente para acompanhar as enormes e rápidas demandas dos modelos de IA. Quando os dados genuínos acabarem, isso representará um grande problema tanto para os desenvolvedores quanto para os usuários de IA.
Isso forçará as empresas de tecnologia a dependerem mais fortemente dos dados gerados pela IA, conhecidos como “dados sintéticos”. E isto, por sua vez, poderá fazer com que os sistemas de IA atualmente utilizados por centenas de milhões de pessoas sejam menos precisos e fiáveis – e, portanto, úteis.
Mas este não é um resultado inevitável. Na verdade, se utilizados e geridos com cuidado, os dados sintéticos poderão melhorar os modelos de IA.

Os problemas com dados reais
As empresas de tecnologia dependem de dados – reais ou sintéticos – para construir, treinar e refinar modelos generativos de IA, como o ChatGPT. A qualidade destes dados é crucial. Dados deficientes levam a resultados fracos, da mesma forma que a utilização de ingredientes de baixa qualidade na cozinha pode produzir refeições de baixa qualidade.
Dados reais referem-se a textos, vídeos e imagens criados por humanos. As empresas os coletam por meio de métodos como pesquisas, experimentos, observações ou mineração de sites e mídias sociais.
Os dados reais são geralmente considerados valiosos porque incluem eventos verdadeiros e capturam uma ampla gama de cenários e contextos. No entanto, não é perfeito.
Por exemplo, pode conter erros ortográficos e conteúdo inconsistente ou irrelevante . Também pode ser fortemente tendencioso , o que pode, por exemplo, levar a modelos generativos de IA que criam imagens que mostram apenas homens ou pessoas brancas em determinados empregos.
Esse tipo de dados também requer muito tempo e esforço para ser preparado. Primeiro, as pessoas coletam conjuntos de dados antes de rotulá-los para torná-los significativos para um modelo de IA. Eles então revisarão e limparão esses dados para resolver quaisquer inconsistências, antes que os computadores os filtrem, organizem e validem.
Este processo pode levar até 80% do tempo total investido no desenvolvimento de um sistema de IA.
Mas, como foi dito acima, os dados reais também são cada vez mais escassos porque os humanos não conseguem produzi-los com rapidez suficiente para alimentar a crescente procura de IA.
A ascensão dos dados sintéticos
Os dados sintéticos são criados artificialmente ou gerados por algoritmos , como um texto gerado pelo ChatGPT ou uma imagem gerada pelo DALL-E .
Em teoria, os dados sintéticos oferecem uma solução econômica e mais rápida para treinar modelos de IA.
Também aborda questões de privacidade e questões éticas , especialmente com informações pessoais sensíveis, como dados de saúde.
É importante ressaltar que, diferentemente dos dados reais, eles não são escassos. Na verdade, é ilimitado.
A partir daqui são apenas dados sintéticos.
-Rohan Paul (@rohanpaul_ai) 9 de janeiro de 2025
“A soma cumulativa do conhecimento humano foi esgotada no treinamento em IA. Isso aconteceu, basicamente, no ano passado.”
– Elon pic.twitter.com/rdPzCbvdLv
Os desafios dos dados sintéticos
Por estas razões, as empresas tecnológicas recorrem cada vez mais a dados sintéticos para treinar os seus sistemas de IA. A empresa de pesquisa Gartner estima que, até 2030, os dados sintéticos se tornarão a principal forma de dados usada em IA.
Mas embora os dados sintéticos ofereçam soluções promissoras, não estão isentos de desafios.
Uma das principais preocupações é que os modelos de IA podem “colapsar” quando dependem demasiado de dados sintéticos. Isto significa que começam a gerar tantas “alucinações” – uma resposta que contém informações falsas – e diminuem tanto em qualidade e desempenho que se tornam inutilizáveis.
Por exemplo, os modelos de IA já têm dificuldade em escrever algumas palavras corretamente. Se esses dados cheios de erros forem usados para treinar outros modelos, eles também replicarão os erros.
Conteúdo de nossos parceiros

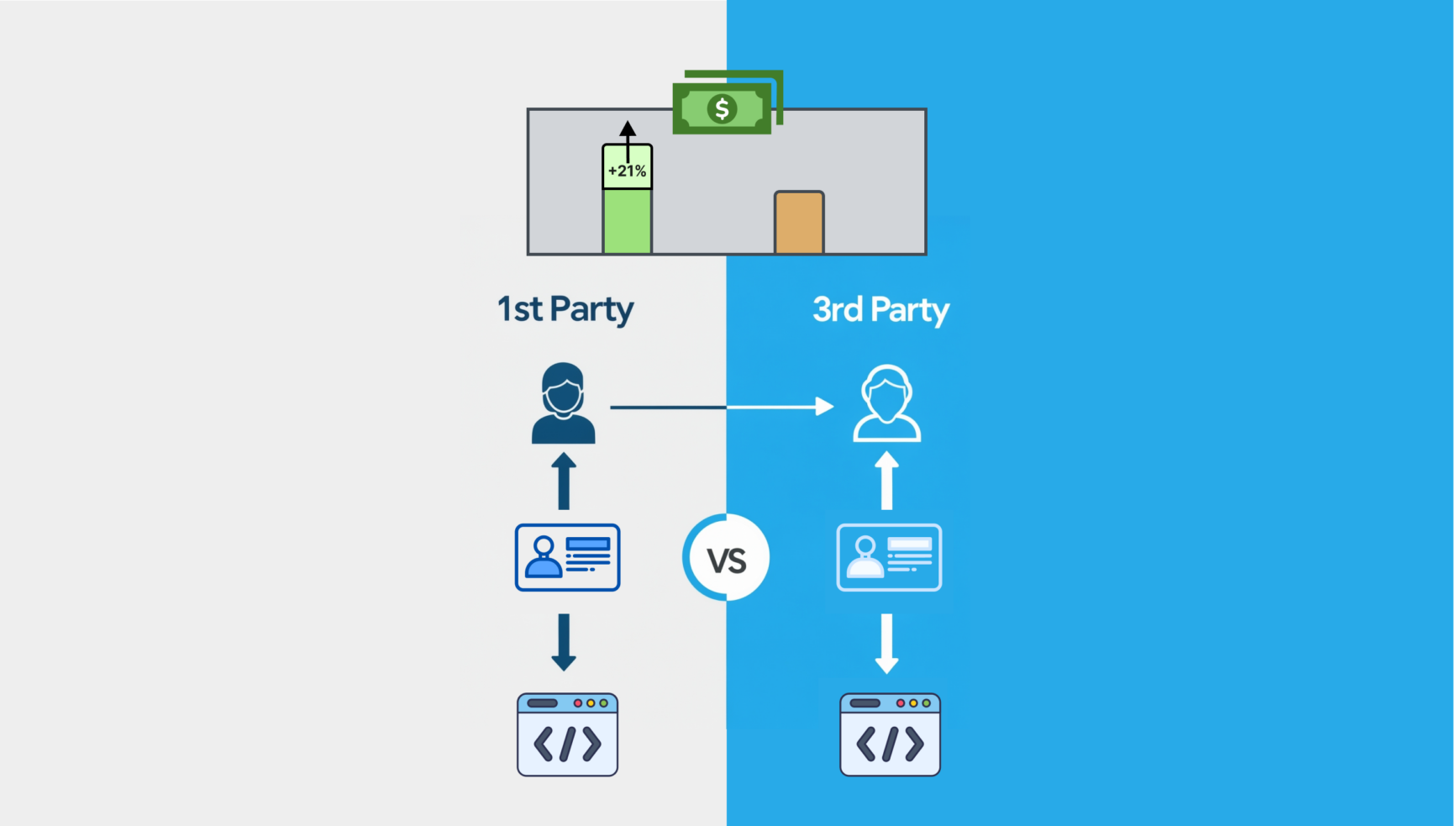
Os dados sintéticos também correm o risco de serem excessivamente simplistas . Pode ser desprovido dos detalhes matizados e da diversidade encontrados em conjuntos de dados reais, o que poderia fazer com que os resultados dos modelos de IA treinados nele também fossem excessivamente simplistas e menos úteis.
Criação de sistemas robustos para manter a IA precisa e confiável
Para resolver estas questões, é essencial que organismos e organizações internacionais, como a Organização Internacional de Normalização ou a União Internacional de Telecomunicações , introduzam sistemas robustos para rastrear e validar dados de formação em IA e garantam que os sistemas possam ser implementados globalmente.
Os sistemas de IA podem ser equipados para rastrear metadados, permitindo que usuários ou sistemas rastreiem as origens e a qualidade de quaisquer dados sintéticos nos quais foram treinados. Isto complementaria um sistema de rastreamento e validação padrão global.
Os humanos também devem manter a supervisão dos dados sintéticos durante todo o processo de treinamento de um modelo de IA para garantir que sejam de alta qualidade. Esta supervisão deve incluir a definição de objetivos, a validação da qualidade dos dados, a garantia da conformidade com os padrões éticos e a monitorização do desempenho do modelo de IA.
Ironicamente, os algoritmos de IA também podem desempenhar um papel na auditoria e verificação de dados, garantindo a precisão dos resultados gerados por IA de outros modelos. Por exemplo, esses algoritmos podem comparar dados sintéticos com dados reais para identificar quaisquer erros ou discrepâncias e garantir que os dados sejam consistentes e precisos. Dessa forma, os dados sintéticos poderiam levar a melhores modelos de IA.
O futuro da IA depende de dados de alta qualidade . Os dados sintéticos desempenharão um papel cada vez mais importante na superação da escassez de dados.
No entanto, a sua utilização deve ser cuidadosamente gerida para manter a transparência, reduzir erros e preservar a privacidade – garantindo que os dados sintéticos servem como um complemento fiável aos dados reais, mantendo os sistemas de IA precisos e fiáveis.
James Jin Kang, professor sênior em ciência da computação, RMIT University Vietnam .
Este artigo foi republicado de The Conversation sob uma licença Creative Commons. Leia o artigo original .






