Publishers invested in appearing at the top of Google’s search results already understand the importance of SEO. One important and potentially overlooked aspect of SEO for bigger publishers, however, is the Google crawl budget.
Google’s crawl budgets help to determine the extent to which articles appear in search results.
Understanding crawl budgets is a critical step towards ensuring that SEO goals are met and that content is viewed. Checking that a site’s technical back end is healthy means the front end is more likely to mirror that status.
In this article we explain what a crawl budget is, what affects the budget, crawl budget optimization, how to check and track crawl budgets and why these budgets are so important to the well-being of any online site.
What Is Crawl Budget?
Crawl budget refers to the resources that Google allocates to the finding and indexation of new and existing web pages.
Google’s crawl bot — Googlebot — crawls sites to update and expand the search giant’s database of web pages. It uses internal and external links, XML sitemaps, RSS and Atom feeds, as well as robots.txt files to help crawl and index sites as quickly as possible.
Certain pages gain more authority over time, while others may be ignored entirely owing to a number of reasons that range from content-related to technical restrictions.
Knowing how to maximize crawl budget is invaluable for any publisher or organizational website looking for success on search engine results pages (SERPs).
Googlebot’s Limitations
Googlebot is not an endless resource and Google cannot afford to trawl through an endless number of web servers. As such, the company has offered guidance to domain owners to maximize their own crawl budget.1
Understanding how bots conduct their activity is foundational.
If a crawlbot comes to a site and determines that analyzing and categorizing it will be problematic, it will slow down or move on to another site entirely depending on the extent and type of issues it faces.
When this happens, it is a clear signal that the site lacks crawl budget optimization.
Knowing that Googlebot is a finite resource should be enough reason for any site owner to worry about crawl budget. However, not all sites face this problem to the same degree.
Who Should Care and Why?
Although every site owner wants their website to succeed, only medium and large sites that frequently update their content really need to worry about crawl budgets.
Google defines medium sites as those with more than 10,000 unique pages that update on a daily basis. Large sites, meanwhile, have over 1 million unique pages and update at least once a week.
Google notes the relationship between crawling activity and larger websites, saying: “Prioritizing what to crawl, when, and how much resource the server hosting the website can allocate to crawling is more important for bigger websites, or those that auto-generate pages based on URL parameters, for example.”2
Sites with limited page numbers need not be overly concerned about crawl budget. However, given that some publishers may expand rapidly, gaining a foundational understanding of crawl stats and operations will put all site owners in a better position to reap the rewards of greater site traffic further down the track.
What Affects Google’s Crawl Budget?
The extent to which Google crawls a website is determined by crawl capacity limits and crawl demand.
In order to prevent crawl activity from overwhelming a host server, the capacity limit is calculated by establishing the maximum number of simultaneous, parallel connections that the bot can use to crawl the site as well as the time delay between data returns.
Crawl Capacity Limit
This metric, which is also referred to as crawl rate limit, is fluid and relates to changes in three factors:
- Crawl health: If the site responds without error or delay, and site speed is good, the limit can rise and vice-versa.
- GSC crawl rate: Google Search Console (GSC) can be used to reduce crawling activity, a function that can be useful during extended site maintenance or updates.3 Any changes remain active for 90 days.4
If the crawl rate limit is listed as “calculated at optimal”, raising it is not an option and lowering it can only happen via special request. If a site is being overcrawled, leading to site availability and/or page load issues, use robots.txt to block crawling and indexing. This option, however, may take 24 hours to come into effect.
While many sites do not impose crawl limit sanctions, it can still be a useful tool.
Crawl Demand
Crawl demand is an expression of how much interest there is from Google in indexing a site. It, too, is influenced by three factors:
- Perceived inventory: Without guidance from the site owner — which we’ll cover a bit later — Google will try to crawl every URL, including duplicates, non-working links and less important pages. This is where narrowing Googlebot’s search parameters can boost crawl budget.
- Popularity: If a site is extremely popular then its URLs will be crawled more often.
- Staleness: Generally, the Googlebot system aims to recrawl pages in order to pick up any changes. This process can be helped along by using the GSC and requesting recrawls, although there is no guarantee the request will be immediately acted upon.
Crawl activity is, in essence, a product of sound website management.
CMS Concerns
Vahe Arabian, founder of State of Digital Publishing (SODP), says that content management system (CMS) elements — such as plug-ins — can affect crawl budgets.5
He said: “Many plug-ins are heavy database driven and cause resource loads to increase that will slow a page down or create unnecessary pages and affect its crawlability.”
A website’s ad-driven revenue model can create similar issues if multiple site features are resource heavy.
How to Check and Track Crawl Budgets
There are two key ways to track crawl budgets: Google Search Console (GSC) and/or server logs.6
Google Search Console
Prior to checking a site’s crawl rates on Google Search Console (GSC), domain ownership must be verified.
The console has three tools to check website pages and confirm which URLs are functional and which have not been indexed.
The console checks for domain inaccuracies and will offer suggestions on how to resolve various crawl errors.
GSC groups status errors into a number of categories in its Index Coverage Report, including:
- Server error [5xx]
- Redirect error
- Submitted URL blocked by robots.txt
- Submitted URL marked ‘noindex’
- Submitted URL seems to be a soft 404
- Submitted URL returns unauthorized request (401)
- Submitted URL not found (404)
- Submitted URL returned 403:
- Submitted URL blocked due to other 4xx issue
The report indicates how many pages have been affected by each error alongside the validation status.
The URL Inspection Tool provides indexing information on any specific page, while the Crawl Stats Report can be used to find out how often Google crawls a site, the responsiveness of the site’s server and any associated availability issues.
There is a fixed approach to identifying and correcting each error, with these ranging from recognizing that a site server may have been down or unavailable at the time of the crawl to using a 301 redirection to redirect to another page, or removing pages from the sitemap.
If page content has changed significantly, the URL Inspection Tool’s “request indexing” button can be used to initiate a page crawl.
While it might not be necessary to “fix” each individual page error, minimizing problems that slow crawl bots is definitely a best practice.
Use Server Logs
As an alternative to the Google Search Console (GSC), a site’s crawl health can be inspected via server logs that not only record every site visit but also each Googlebot visit.
For those not already in the know, servers automatically create and store a log entry whenever Googlebot or a human request a page be served. These log entries are then collected in a log file.
Once a log file has been accessed, it needs to be analyzed. However, given the sheer scope of log entries this endeavor should not be undertaken lightly. Depending on the size of the site, a log file can easily contain hundreds of millions or even billions of entries.
If the decision is made to analyze the log file, the data needs to be exported into either a spreadsheet or a proprietary piece of software, more easily facilitating the analysis process.
Analysis of these records will show the type of errors a bot has faced, which pages were accessed the most and how often a site was crawled.
9 Ways to Optimize Crawl Budget
Optimization involves checking and tracking site health statistics, as noted above, then directly addressing problem areas.
Below we’ve laid out our crawl budget optimization toolkit, which we use to address crawlability issues as they arise.
1. Consolidate Duplicate Content
Crawl issues can appear when a single page is either accessible from a number of different URLs or contains content that is replicated elsewhere on the site. The bot will view these examples as duplicates and simply choose one as the canonical version.
The remaining URLs will be deemed less important and will be crawled less often or even not at all.10 This is fine if Google picks the desired canonical page, but is a serious problem if it does not.
That said, there may be valid reasons to have duplicate pages, such as a desire to support multiple device types, enable content syndication or use dynamic URLs for search parameters or session IDs.
SODP’s recommendations:
- Prune website content where possible
- Use 301s to consolidate URLs and merge content
- Delete low performing content
- Using 301s following a website restructure will send users, bots and other crawlers where they need to go.
- Use noindex for thin pages, pagination (for older archives) and for cannibalizing content.
- In cases where duplicate content leads to over crawling, adjust the crawl rate setting in Google Search Console (GSC).
2. Use Robots.txt File
This file helps prevent bots from trawling through an entire site. Using the file allows for the exclusion of individual pages or page sections.
This option gives the publisher control of what is indexed, keeping certain content private while also improving how the crawl budget is spent.
SODP’s recommendations:
- Order the preference of parameters in order to prioritize the parameters that need to be blocked from crawling.
- Specify robots, directives and parameters that are causing additional crawl using log files.
- Block common paths that CMS’ typically have such as 404, admin, login pages, etc.
- Avoid using crawl-delay directive to reduce bot traffic for server performance. This only impacts new content indexation.
3. Segment XML Sitemaps to Ensure Quicker Content Pick Up
A crawl bot arrives at a site with a general allocation of how many pages it will crawl. The XML sitemap effectively directs the bot to read selected URLs, ensuring the effective use of that budget.
Note that a page’s ranking performance depends on several factors including content quality and internal/external links. Consider including only top-tier pages in the map. Images can be allocated their own XML sitemap.
SODP’s recommendations:
- Reference the XML sitemap from the robots.txt file.
- Create multiple sitemaps for a very large site. Don’t add more than 50,000 URLs to a single XML sitemap.
- Keep it clean and only include indexable pages.
- Keep the XML sitemap up-to-date.
- Keep the file size to less than 50MB.
4. Examine the Internal Linking Strategy
Google follows the network of links within a site and any pages with multiple links are seen as high-value and worth spending the crawl budget on.
However, it’s worth noting that while a limited number of internal links can work against the crawl budget, so too can peppering the entire site with links.
Pages without internal links receive no link equity from the rest of the website, encouraging Google to treat them as being of lower value.
At the same time, high-value pages that contain a lot of internal links end up sharing their link equity equally between other pages regardless of their strategic value. As such, avoid linking to pages that offer little value to readers.
An internal linking strategy requires a deft touch to ensure that high-value pages receive enough links, while low-value pages do not cannibalize link equity.
5. Upgrade Hosting if Concurrent Traffic is a Bottleneck
If a website runs on a shared hosting platform, crawl budget will be shared with other websites running on said platform. A large company may find independent hosting to be a valuable alternative.
Other considerations when upgrading your hosting or even before upgrading to resolve bot traffic overload that can impact server loads:
- Process images using a separate CDN that is also optimized to host next gen image formats such as webp
- Consider hosting CPU, disk space based on your website function and requirements
- Monitor activity using solutions like New Relic to monitor excess usage of plugins and bots
6. Balance Javascript Usage
When Googlebot lands on a web page it renders all the assets on said page, including Javascript. While crawling HTML is rather straightforward, Googlebot must process Javascript a number of times in order to be able to render it and understand its content.
This can quickly drain Google’s crawl budget for a website. The solution is to implement Javascript rendering on the server side.
By avoiding sending Javascript assets to the client for rendering, crawl bots don’t expend their resources and can work more efficiently.11
SODP’s recommendations:
- Use browser-level-lazy loading instead of being JS based
- Determine whether elements
- Use server side tagging for analytics and third-party tagging, either self-hosted or using solutions such as https://stape.io/.12
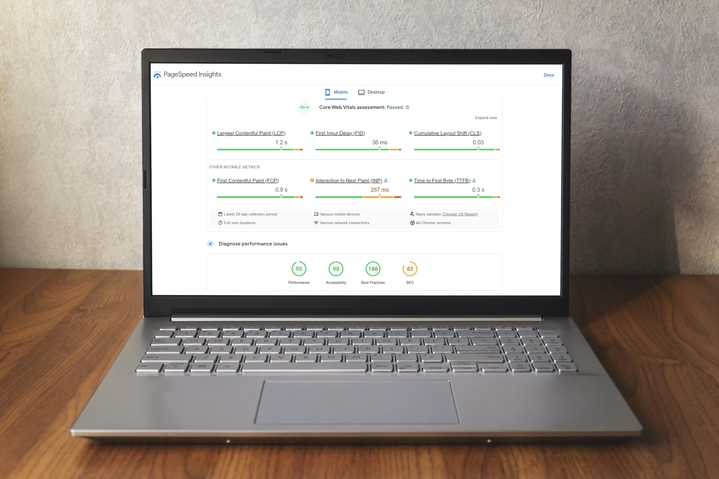
7. Update Core Web Vitals (CWV) to Improve Page Experience
Google Search Console’s (GSC) Core Web Vitals (CWV) uses what the search giant calls “real world usage data” to show page performance.13
The CWV report groups URL performance under three categories:
- Metric type ( LCP, FID and CLS)
- Status
- URL groups
Metric
The CWV report is based on the largest contentful paint (LCP),14 first input delay (FID)15 and cumulative layout shift (CLS)16 metrics.
LCP relates to the amount of time it takes to render the largest content element visible on the web page’s visible area.
FID concerns the time it takes for a page to respond to a user’s interaction.
CLS is a measurement of how much the page layout shifts during the user session, with higher scores representing a worse user experience.
Status
Following a page assessment, each metric is assigned one of three status ranks:
- Good
- Needs improvement
- Poor
URL Groups
The report can also assign issues to a group of similar URLs, assuming that performance issues affecting similar pages can be attributed to a shared problem.
CWV and Crawlability
As noted before, the longer Googlebot spends on a page, the more it squanders its crawl budget. As such, publishers can use the CWV reports to optimize page efficiency and cut down on crawl time.
SODP’s recommendations, with a focus on WordPress:
| Speed improvement pointers | Implement via | Validate on |
| Convert images to WebP format | If CDN is enabled then convert it via CDN side or install EWWW plugin | https://www.cdnplanet.com/tools/cdnfinder/ |
| Implement SRCSET & Check in https://pagespeed.web.dev/ if the Properly size images issue is resolved | Implement by adding code manually | Check in browser code if all the images have the SRCSET code |
| Enable browser caching | WP rocket | https://www.giftofspeed.com/cache-checker/ |
| Lazy load images | WP rocket | Check in the browser console if the lazyload code is added to the image. Except for the featured image. |
| Defer external scripts: Only the scripts in the <body> can be deferred | WP rocket or A faster website! (aka defer.js) plugin | After add the defer tag check in https://pagespeed.web.dev/ if the Reduce unused JavaScript issue is resolved |
| Identify and remove unused JS and CSS files | Manually | |
| Enable Gzip compression | Server side, contact hosting provider | https://www.giftofspeed.com/gzip-test/ |
| Minify JS and CSS | WP rocket | https://pagespeed.web.dev/ |
| Load fonts locally or Preload web fonts | OMG font plugin or upload the font files on server and add it via code in the header | |
| Enable CDN | Cloudflare (any other CDN service) and configure it for the site |
8. Use a Third-Party Crawler
A third-party crawler such as Semrush, Sitechecker.pro or Screaming Frog allows web developers to audit all the URLs on a site and identify potential issues.
Crawlers can be used to identify:
- Broken links
- Duplicate content
- Missing page titles
These programs offer a crawl stats report to help highlight problems that Google’s own tools may not.
Improving structured data and cutting down on hygiene issues will streamline Googlebot’s job of crawling and indexing a site.
SODP’s recommendations:
- Use SQL queries to conduct batch updates to errors instead of manually fixing each issue.
- Emulate Googlebot, via search crawl settings, to prevent being blocked from hosting providers and to properly identify and fix all technical issues.
- Debug missing pages from a crawl using this great guide from Screaming Frog.17
9. URL Parameters
URL parameters — the section of the web address that follows the “?” — are used on a page for a variety of reasons, including filtering, pagination and searching.
While this can boost the user experience, it can also cause crawling issues when both the base URL and one with parameters return the same content. An example of this would be “http://mysite.com” and “http://mysite.com?id=3” returning the exact same page.
Parameters allow a site to have a near unlimited number of links — such as when a user can select days, months and years on a calendar. If the bot is allowed to crawl these pages, the crawl budget will be used up needlessly.
SODP’s recommendations:
- Use robots.txt rules. For example, specify parameter orders in an allow directive.
- Use hreflang to specify content’s language variations.
Round Up of Googlebot Myths and Facts
There are several misconceptions regarding Googlebot’s power and scope.
Here are five we’ve explored:
1. Googlebot Intermittently Crawls a Site
Googlebot actually crawls sites fairly frequently and, in some situations, even daily. However, the frequency is determined by the site’s perceived quality, newness, relevance and popularity.
As noted above, the Google Search Console (GSC) can be used to request a crawl.
2. Googlebot Makes Decisions About Site Ranking
While this used to be correct, Google now considers this to be a separate part of the crawl, index and rank process, according to Martin Splitt, WebMaster Trends Analyst at Google.18
However, it’s also important to remember that a site’s content, sitemap, number of pages, links, URLs, etc. are all factors in determining its ranking.
In essence, savvy SEO choices by publishers can lead to solid positioning within the SERPs.
3. Googlebot Invades Private Sections of a Site
The bot has no concept of “private content” and is simply tasked with indexing sites unless directed by the site owner to do otherwise.
Certain web pages can remain unindexed as long as the necessary steps within the GSC are taken to restrict access.
4. Googlebot Activity Can Put a Strain on Site Workability
The Googlebot process has its limitations both because of Google’s resource limitations and because Google doesn’t want to disrupt a site.
Splitt said: “We crawl a little bit, and then basically ramp it up. And when we start seeing errors, we ramp it down a little bit.”15
The GSC can delay crawls and given some sites may have a few hundred thousand pages, Googlebot breaks up its crawl over several visits.
5. Googlebot is the Only Bot Worth Worrying About
While Googlebot is the world’s leading crawler, not all bots belong to Google. Other search engines crawl the web, while bots that focus on analytics as well as data and brand safety are also active.
At the same time, bad actors are designing ever-more sophisticated software to engage in ad fraud, steal content, post spam and more.19
Final Thoughts
It is important to remember that crawl budget optimization and successful user experiences can both be managed without compromising the other
Checking a site’s crawl budget health should be an element of all website owners’ maintenance programs, with the frequency of these checks depending upon the size and nature of the website itself.
Technical housekeeping — such as fixing broken links, non–working pages, duplicated content, poorly worded URLs and old, error-laden sitemaps — is also essential.
- Crawl Budget Management For Large Sites | Google Search Central | Documentation
- What Crawl Budget Means for Googlebot | Google Search Central Blog
- Reduce Googlebot Crawl Rate | Google Search Central | Documentation
- Change Googlebot crawl rate – Search Console Help
- Crawl Budget Optimization for Publishers | State of Digital Publishing
- Google Search Console
- Index Coverage report – Search Console Help
- URL Inspection Tool – Search Console Help
- Crawl Stats report – Search Console Help
- Consolidate Duplicate URLs with Canonicals | Google Search Central | Documentation
- Rendering on the Web | Google Developers
- Stape.io
- Core Web Vitals report – Search Console Help
- Largest Contentful Paint (LCP)
- First Input Delay (FID)
- Cumulative Layout Shift (CLS)
- How To Debug Missing Pages In A Crawl – Screaming Frog
- Googlebot: SEO Mythbusting
- Ad Fraud: Everything You Need to Know | Publift