

中国新的DeepSeek大语言模型(LLM)破坏了美国统治的市场,以相对较高的聊天机器人模型的成本明显降低。
与美国AI工具相比,开发成本和降低的订阅价格降低了,有助于美国芯片制造商在一天内损失了6000亿美元 NVIDIA使计算机芯片用于训练大多数LLM,这是Chatgpt和其他AI聊天机器人中使用的基础技术。 DeepSeek在更昂贵的最新版本上使用了便宜的NVIDIA H800芯片。
据报道,Chatgpt开发人员Openai花费了1亿至10亿美元,开发了其最新版本的产品O1。相比之下,DeepSeek在短短两个月内完成了培训,使用了一系列巧妙的创新,耗资560万美元。
但是,DeepSeek的AI聊天机器人R1的表现如何与其他类似的AI工具相比?
DeepSeek声称其模型与OpenAI的产品相当,甚至超过了某些基准测试中的O1模型。但是,使用大量多任务语言理解(MMLU)测试的基准测试使用多项选择问题评估多个受试者的知识。许多LLM经过培训和优化此类测试,使其成为现实性能的真实指标。
对LLM的客观评估的替代方法使用了加的夫大都会,布里斯托尔和卡迪夫大学的研究人员开发的一组测试 - 统称为知识观察小组(KOG)。这些测试通过需要隐含的人类理解来回答的问题来探究LLMS模仿人类语言和知识的能力。核心测试是秘密的,以避免LLM公司培训其模型进行这些测试。
Meta的数据科学家Colin Fraser启发的公共测试,以评估针对其他LLM的DeepSeek。观察到以下结果:
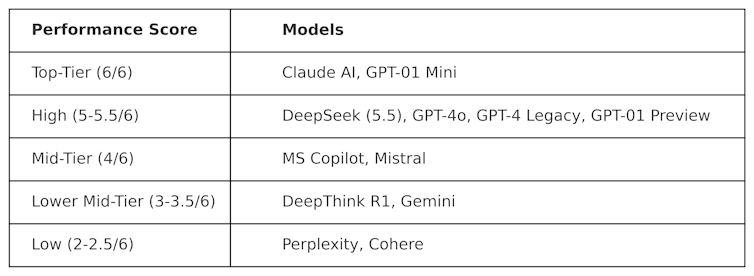
用于生产此表的测试本质上是“对抗性的”。换句话说,它们被设计为“硬”,并以对其设计方式不同情的方式测试LLM。这意味着在此测试中这些模型的性能可能与它们在主流基准测试中的性能不同。
DeepSeek在6分中得分5.5,表现优于Openai的O1(其先进的推理(称为“经营链”)模型,以及Chatgpt-4O(免费版本的Chatgpt)。但是DeepSeek的表现略高于Anthropic的Claudeai和Openai的O1 Mini,两者均得分为6/6。有趣的是,O1的表现不佳与其“较小”的O1 Mini相对。
DeepThink R1(DeepSeek制造的经过深思熟虑的AI工具)的表现与DeepSeek的表现不佳,得分为3.5。
该结果表明了DeepSeek的聊天机器人已经有多多,击败了Openai的旗舰车型。对于DeepSeek来说,这可能会促进进一步的发展,而DeepSeek现在有一个坚实的基础可以建立。但是,中国科技公司确实有一个严重的问题:另一个LLMS没有:审查制度。
审查挑战
尽管表现出色和受欢迎程度,DeepSeek仍在对中国对政治敏感话题的反应中面临批评。例如,与天安门广场,台湾,穆斯林和民主运动有关的提示得到了回应:“对不起,这超出了我目前的范围。”
但是,这个问题不一定是DeepSeek独有的,而在LLMS中,政治影响力和审查的潜力通常是日益关注的问题。唐纳德·特朗普(Donald Trump)宣布了5000亿美元的星际之门LLM项目,包括Openai,Nvidia,Oracle,Microsoft和Arm,也引起了人们对政治影响的担忧。
此外,梅塔(Meta)最近决定放弃在Facebook和Instagram上进行事实核对的表明,越来越多的趋势朝着民粹主义而来。
来自我们合作伙伴的内容



DeepSeek的到来对LLM市场造成了严重破坏。 OpenAI和Anthropic等美国公司将被迫创新其产品,以保持相关性并符合其性能和成本。
DeepSeek的成功已经在挑战现状,表明可以在没有数十亿美元预算的情况下开发高性能的LLM模型。它还强调了LLM审查制度的风险,错误信息的传播以及独立评估的原因。
随着LLM越来越深入的全球政治和商业,透明度和问责制对于确保LLM的未来是安全,有用和值得信赖至关重要的。






